
AWS-Powered Document Intelligence with RAG
Wiran Larbi / March 15, 2025
Overview
A scalable document intelligence platform enabling:
- PDF-to-Knowledge conversion pipeline
- Context-Aware Q&A with LLM synthesis
- Zero-Downtime AWS deployment
Document Processing Pipeline
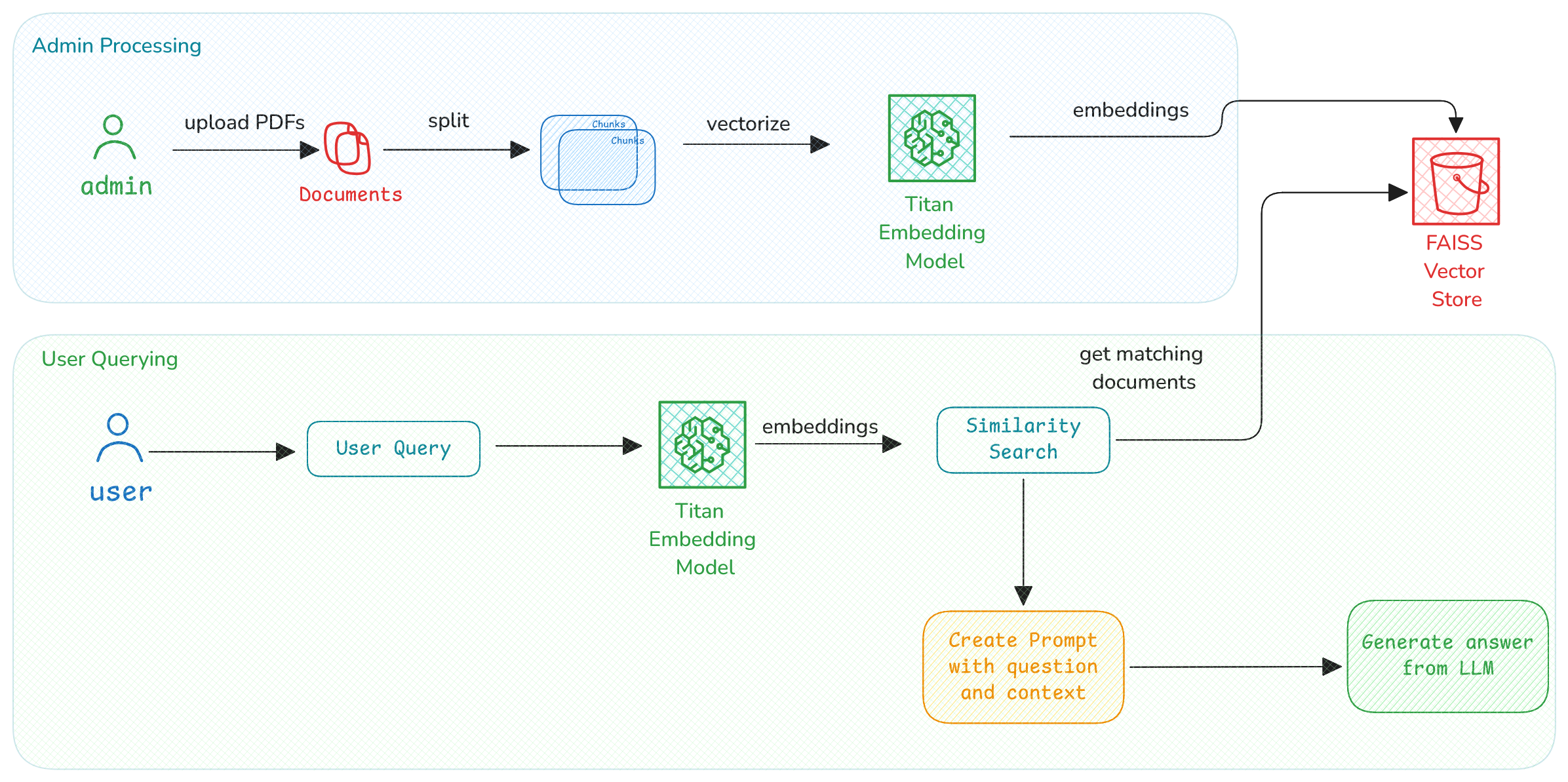
Stage 1: Ingestion & Preparation
-
PDF Upload
Users submit documents through admin interface -
Document Chunking
Split PDFs into semantic text segments (paragraphs/sections) -
Vector Encoding
Convert chunks to embeddings using Amazon Titan model -
Vector Storage
Index embeddings in FAISS with metadata pointers
Stage 2: Question Answering
-
Query Input
Receive natural language question from user -
Query Encoding
Convert question to vector using Tim model (query-optimized variant) -
Context Retrieval
Find top-K matching chunks via FAISS similarity search -
Answer Synthesis
Augment LLM (GPT/Claude) with context to generate final response## Document Processing Pipeline
AWS Infrastructure Blueprint
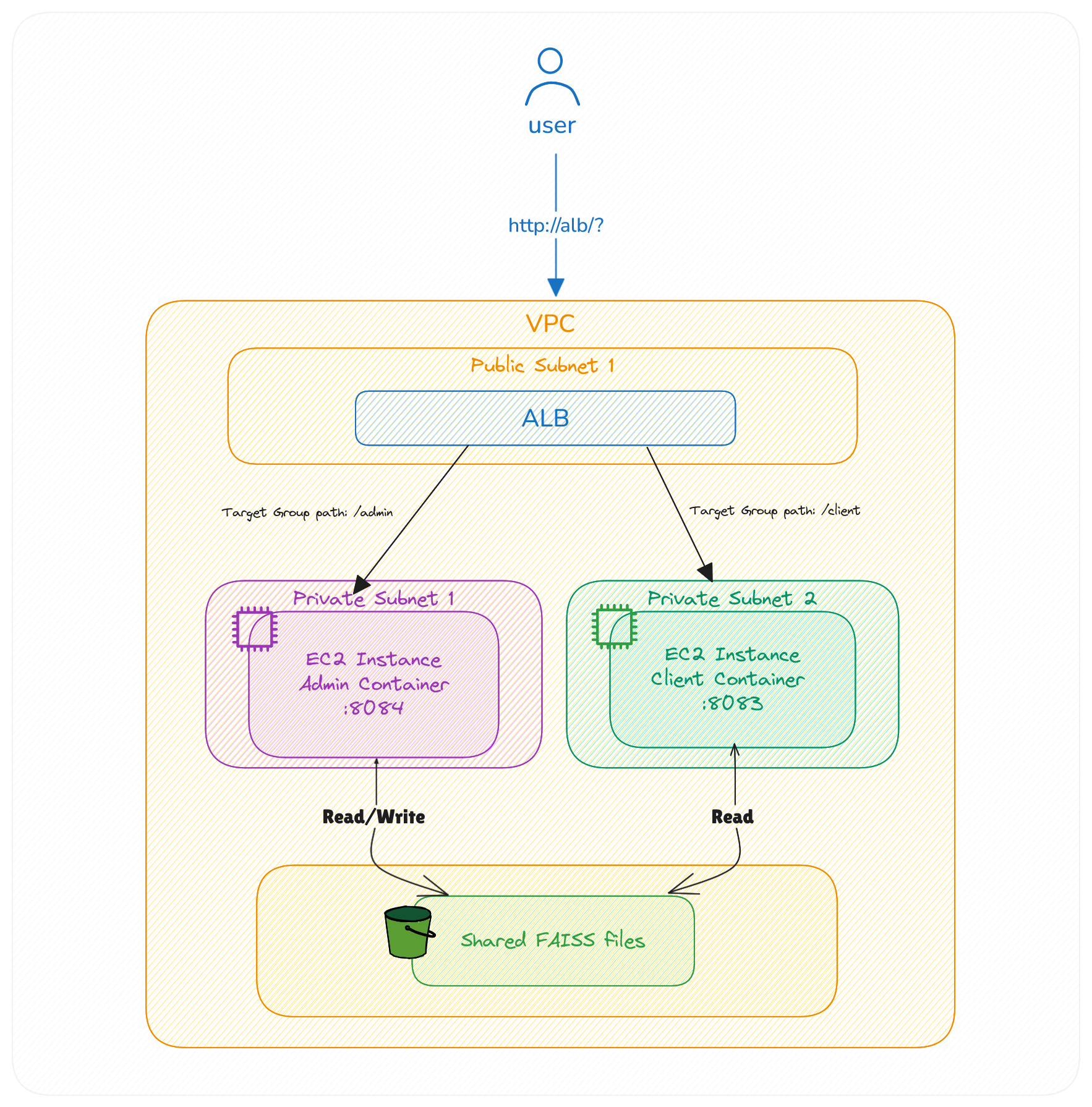
VPC Layout
VPC:
PublicSubnets:
- CIDR: 10.0.1.0/24
AZ: us-east-1a
PrivateSubnets:
- CIDR: 10.0.2.0/24
AZ: us-east-1b
- CIDR: 10.0.3.0/24
AZ: us-east-1c
SecurityGroups:
ALB-SG:
Ingress:
- Protocol: TCP
Ports: [80, 443]
EC2-SG:
Ingress:
- Protocol: TCP
Ports: [8083-8084]
Source: ALB-SGEC2 Configuration
[admin-instance]
ami = "ami-0abcdef1234567890"
type = "t3.small"
ports = [8084]
storage = { type = "gp3", size = 8 }
[client-instance]
ami = "ami-0abcdef1234567890"
type = "t3.small"
ports = [8083]
storage = { type = "gp3", size = 8 }Deployment Guide
Prerequisites
- AWS Account with IAM permissions
- Docker installed
- FAISS model binaries to be created in S3
Service Deployment
Admin Service Dockerfile
FROM python:3.11
EXPOSE 8083
WORKDIR /app
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY . ./
ENTRYPOINT [ "streamlit", "run", "admin.py", "--server.port=8083", "--server.address=0.0.0.0" ]Client Service Dockerfile
FROM python:3.11
EXPOSE 8084
WORKDIR /app
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY . ./
ENTRYPOINT [ "streamlit", "run", "client.py", "--server.port=8084", "--server.address=0.0.0.0" ]Deployment Script
# Build the Docker images
docker build -t rag-admin:latest -f admin.Dockerfile .
docker build -t rag-client:latest -f client.Dockerfile .
# Run the containers
docker run -d \
--name rag-admin \
-p 8083:8083 \
--restart unless-stopped \
rag-admin:latest
docker run -d \
--name rag-client \
-p 8084:8084 \
--restart unless-stopped \
rag-client:latestAccess Endpoints
- Admin API:
https://api.example.com/admin(HTTPS, IAM Role authentication) - Client API:
https://api.example.com/client(HTTPS, API Key/Bearer authentication) - Metrics:
internal:9090/metrics(HTTP, VPC Peering authentication)
FAQ
How is FAISS storage synchronized between instances?
We use an S3-backed synchronization layer that:
- Maintains a primary FAISS index in us-east-1
- Replicates to read-only replicas in other regions
- Uses versioned S3 objects for consistency
Important: Ensure proper VPC peering configuration when accessing from other AWS services!